16 ways to improve your load test scenarios: Ensure the validity of your performance tests, avoid breaking stuff, and grow your tests over time with the right strategy
Before we start
So you’ve written your first load test? Maybe you read the basic documentation (Locust, JMeter, k6), and got to a place where you actually have something running. That’s great! Now there are some things you can do to get the most out of your load tests…
Ensure test validity
1. Validate response content, not just status codes
When a performance test ‘passes’ you want to know that the end result is actually what you expect. Most load testing tools will automatically check the HTTP status code and mark requests as passed or failed, but often that is not enough. Sometimes a “200 OK” response actually contains an error message, or is technically correct, but didn’t do what you expected it to. This is something that needs to be tuned for your specific test case and if you want to be really sure, you should both check for errors and check for the positive outcome (e.g. If you’re testing a checkout flow you want to see a “Thanks for your order” page or maybe an order ID).
It’s preferable to check something in every response, but at a minimum you should the final step in a flow. If an earlier step has failed (login, add product to cart) then you can often detect that in a later step (checkout).
In JMeter you can use the various types of Assertions, in k6 you use checks. In Locust you just use plain Python to do the validation and then call the .failure() method of the response as needed:
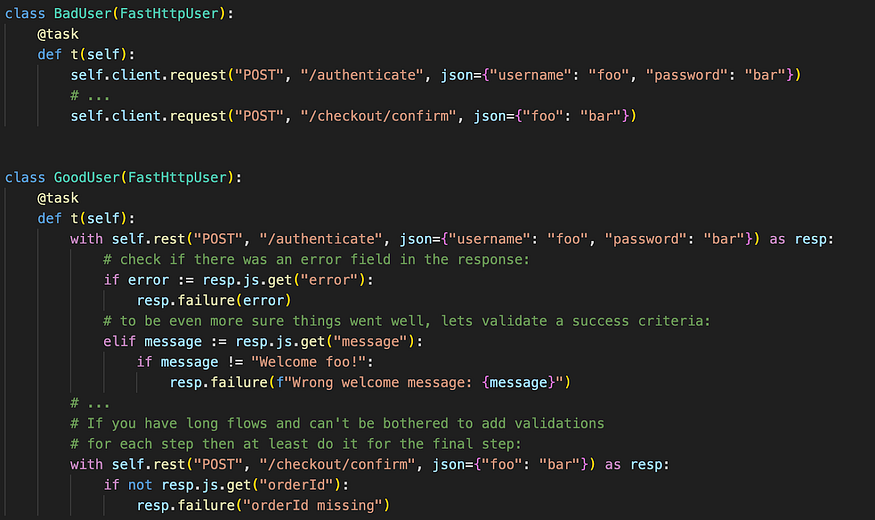
These two Users behave identically as long as things go well, but the second one will give you earlier and more detailed information if things go wrong.
These two Users behave identically as long as things go well, but the second one will give you earlier and more detailed information if things go wrong.
For validating or processing HTML responses, there are many options, BeautifulSoup and PyQuery are some examples.
2. Abort flows when you get an error
Your performance test scenarios need to closely approximate reality, including mimicking what a user would actually do. If your webshop requires customers to open or sign into an account before placing an order, a customer that fails to log in won’t try to place an order. If your test doesn’t exit the flow early, it might attempt to do just that though, which can trigger a flood of errors that would never happen in real life.
Errors can be useful clues for identifying bottlenecks and other issues, but in this situation it’s easy to get red herrings that could be avoided by exiting the flow. If you have a background in functional testing, this will seem obvious, but most load testing tools don’t abort flows early by default so it’s something to look out for.
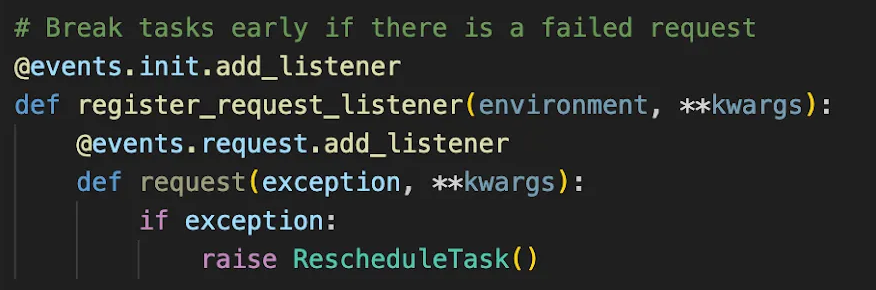
Yeah, this isnt the easiest code to understand. You can use the pre-packaged version from locust-plugins if you prefer
3. Use sleeps between page loads/clicks
A real user will always take a second or two before initiating the next action. Unrealistically fast “users” might expose errors a real user would never see, so it’s worth building in sleeps or “think time” between actions in your test scenarios to ensure realistic user behavior.
4. Use retries with caution
If you’re testing a system and you encounter occasional failures, you may be drawn to using some retry mechanic. Your first thought should of course be to investigate the error rather than potentially hiding it using a retry. But sometimes this is not possible (if the failure is a known issue), or it is irrelevant (e.g. when a real client would automatically or manually retry).
There are also cases when you are most interested in testing the final step (e.g. actual order completion or payment), because that is most important from a business perspective, or causes the most load on your system. It may make sense then to add retries to a flaky intermediate step, just to ensure your users reach the final step. When trying to find the root cause of an issue, it can also be helpful to use retries to differentiate “intermittent or timing-related” issues from “permanent but rare” ones.
The difference between load testing and functional testing is that the sheer number of requests sometimes makes it impossible to ensure 100% reliability, so retries may be a necessary workaround. It usually isn’t important that every single request during a long test run is successful, and with limited time you will often end up having to turn a blind eye to something like a 0.2% failure rate.
You can read more about using automated retries in testing here.
5. Weight your requests/tasks realistically
Weighting your tasks proportionate to expected traffic or activity will give you a more accurate reflection of your throughput. If most of your customers don’t actually place an order (or create an account, or download a file, or whatever your most intensive task is), your load test scenarios should probably include a much higher frequency of browsing actions than anything else.
6. Use realistic test data
Using the same customer details every time can make your system perform worse (or better — which is even worse from a test perspective). Or it might not work at all, since many systems won’t allow the same customer to have multiple concurrent logins, for example.
Keeping a list of users in a simple CSV file can get you quite far, and if that is not enough you can switch to a database. Having users stored in a database gives you the ability to update test data too, which is useful for stateful tests. You could, for example, set a flag showing whether a customer has placed orders, and make a request to list them only if they do. Many solutions exist but I like MongoDB for its flexibility, or Postgres.
It’s not just about customer data either. For the most realistic results you may need to parametrize things like product IDs, customer IP addresses, etc.
In Locust you read the CSV/database as you would from any other Python program. locust-plugins provides wrappers for distributing data from master to workers, and for reading from CSV and MongoDB. JMeter has its CSV Data Set Config, as well as others.
When you are performance testing one of the key things to remember is “Don’t break stuff”. This is of course even more important if you dont have a dedicated performance test environment, and share it with other testers or even real end users. But either way, here are some tips:
7. Start small
Ideally, with just a single user and carefully increase load, monitoring manually to see if your system can cope. This way you avoid generating lots of data and logs that obscure the actual performance results and generally make it hard to figure out where things are going wrong. (You can also read more about the different types of load profiles and workload models in load testing).
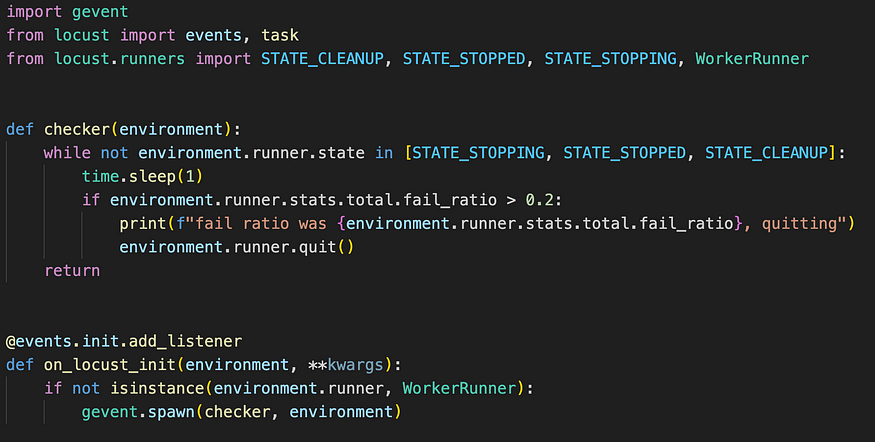
8. Abort mission if errors are spiking
If all goes well and you’re gradually increasing the load, you might hit a threshold where everything starts erroring out. If the error ratio is way too high, just abort the whole test. You want to be able to focus on errors with messages that give you some indication of what is about to happen (such as “queue full” or “timeout” errors) — letting things spiral out of control can lead to an “internal server error” message that doesn’t give much clue about where the problem is.
In tools like Locust, you can even automate this behavior:
Debugging & future proofing your tests
9. When something breaks and you can’t figure out why:
There are of course a thousand things that can go wrong in a test, but here are some tips to help you dig into why a request is failing:
- Go back to running a single user (some load testing tools have a special mode for this with extra logging etc)
- Test in a debugger. This allows you to examine requests/responses in detail and explore all the available fields of the various objects available to your script. Here’s an example of debugging in Locust using VS Code.
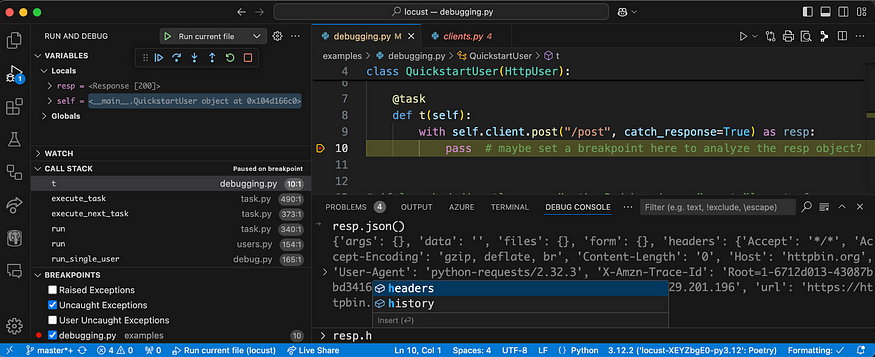
Here we use the debug console to print the JSON body of the response and explore object fields starting with “h”.
When your system doesn’t perform as well as you’d expect
While this is usually an indication it’s time to investigate the system itself, sometimes your load might not be realistic enough. If you think it is not a real problem with the system you are testing (e.g. if you’re seeing significantly worse performance than with real users in production):
10. Ensure load balancers handle test traffic correctly
If load is coming from only one or a few machines, load balancing may not distribute traffic as evenly as it would when thousands of users are accessing your site, especially if the load balancing algorithm is based on IP address.
11. Ensure load generators have plenty of available bandwidth and other resources like CPU
Some tools, like Locust, will inform you if there is an issue with CPU, so check the logs of your load testing tool. Using a cloud hosted load generation solution like Locust Cloud takes some of that responsibility off your hands.
12. Use a realistic ramp-up phase
If your systems need time to warm up or rely on autoscaling, adding users faster than they would arrive in reality can result in unrealistically poor performance.
Growing and maturing your tests
If you’ve got this far, congrats! Even if you don’t iterate any further on your load test scenarios, you’re already doing more than most. If you do want to go further, here are some tips for more mature load test scenario practices.
13. Build abstractions in your test framework
If you find yourself repeatedly implementing something in your test scripts (e.g. a login flow, a retry mechanic, or checking responses for a particular field in the response), write an abstraction for it. This could be a function, a class, or whatever fits best. Below are some examples of how you might do this in Locust:
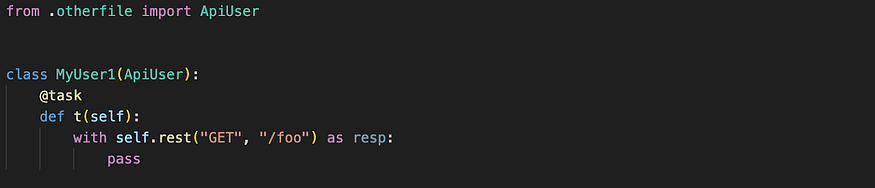
Use class inheritance
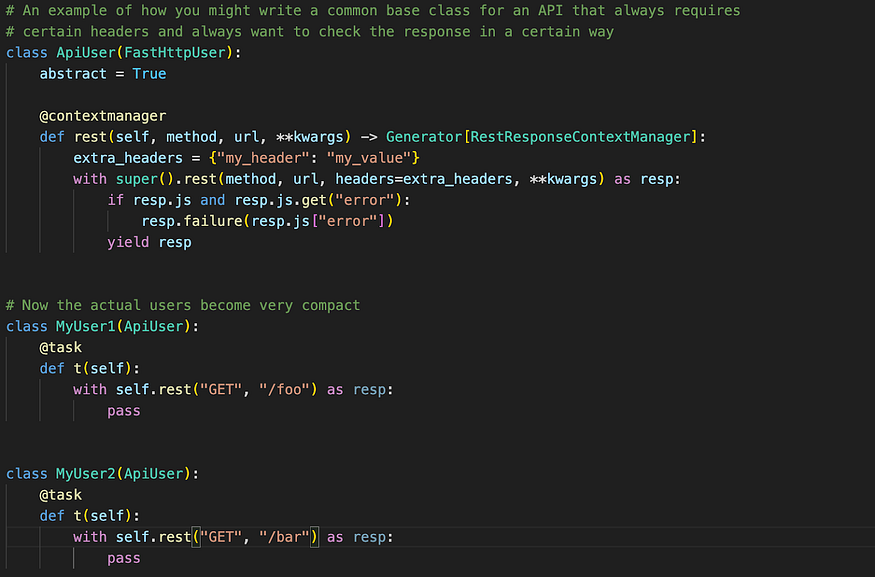
You can even put your base class (ApiUser in this case) in a separate file and import it into your locustfile.
14. But don’t go too far with abstractions
If you abstract things to a “business level” (like “create report”) it’s less clear what the test does, not just for you coming back to it later, but also for any new team members as well.

In general, I would say: avoid expressing tests in functional code or meta-programming/DSLs. Most tests are inherently stateful and the same goes for load testing. While some tests can be expressed in a more compact format using DSLs, a lot of technical context is lost and debugging them is often a pain. Remember, all abstractions are leaky!
16. Avoid too much randomness in your test scenarios

In testing and load testing specifically, you need to implement variations in user behaviors — whether it be the order in which pages are loaded, which items to add to a shopping cart, etc. Sometimes an efficient way to program this is by using randomness. Usually this is fine, and as long as you run the test long enough the actual task executions/requests sent should converge to the weight you have given them.
But there is a risk to this: If there is an infrequent error or a variation between test runs, how do you know this wasn’t caused by the randomness in the scenario itself? I recommend avoiding true randomness. Instead you can use a shuffled list (also known as “deck of cards random”) which will ensure the request distribution converges much faster. You may also want to use seeded random.
Summary
If after all this you still find yourself having to debug an onslaught of errors, don’t panic! That is part of the process. While there is a lot you can do upfront to write realistic and well-defined load test scenarios, most of the work will be in refining your scenarios once you start running tests and gathering results.
Lars Holmberg • 2024-11-07
Back to all posts