Locusts and Honey Badgers - Closed vs Open Workload Models in Load Testing
Locusts and Honey Badgers — Closed vs Open Workload Models in Load Testing
Welcome back to load testing 101! In this series, we started out by explaining the goals of load testing and the role of a performance tester, and then went on to explain the types of load profiles you might need and when to use them. Today is about the pros and cons of open vs. closed workloads. As always, please comment if you have questions!
This series of articles is based on my nearly 20 years of experience with performance testing in gaming, e-commerce, network infrastructure and finance. I maintain the open source load testing tool Locust, and recently started Locust Cloud so you don’t have to do the heavy lifting of setting up and maintaining load testing infrastructure.
What are open and closed workload models?
Open and closed workload models are two different ways to define the load on your system.
In an open workload, requests are sent at a certain rate, regardless of the system’s response times or the number of requests currently being processed.
In a closed workload, only a certain number of concurrent users are running, and the request rate is implicitly limited by the response times of your system, because a user can’t trigger a new request until the previous one has completed.
Closed workload: Find your throughput limit without breaking the system
In Locust, and most other load testing tools, you specify how many concurrent users (threads in JMeter, virtual users in LoadRunner — formerly known as just locusts in Locust) you want to run, and thus the workload model is closed by default.
With a closed load, you would simulate (for example) 100 concurrent users, doing consecutive requests as fast as possible or with some constant amount of sleep in between each request or iteration. Typically you would start with a few users/threads and add more until your system is completely saturated. At that point you’ll either start seeing response times increase significantly, or errors start to appear.
The primary result/outcome variable of closed workload test is achieved throughput, typically measured in requests or transactions per second.
class ClosedWorkload(HttpUser):
wait_time = constant(10) # sleep 10s after each task, regardless of execution time
@task
def my_task(self):
...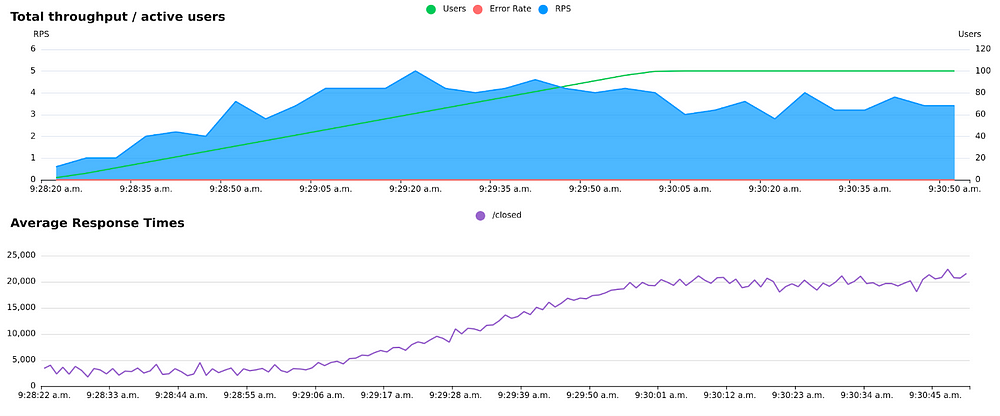
Ramp up using closed load. Notice how as new users are added, the response times start increasing and throughput starts to flatten, but the system is not completely overwhelmed. (Graphs are from locust.cloud)
As the test continues, it is clear that this system can’t really handle more than around 4 requests/s, even if we were to accept these very long response times.
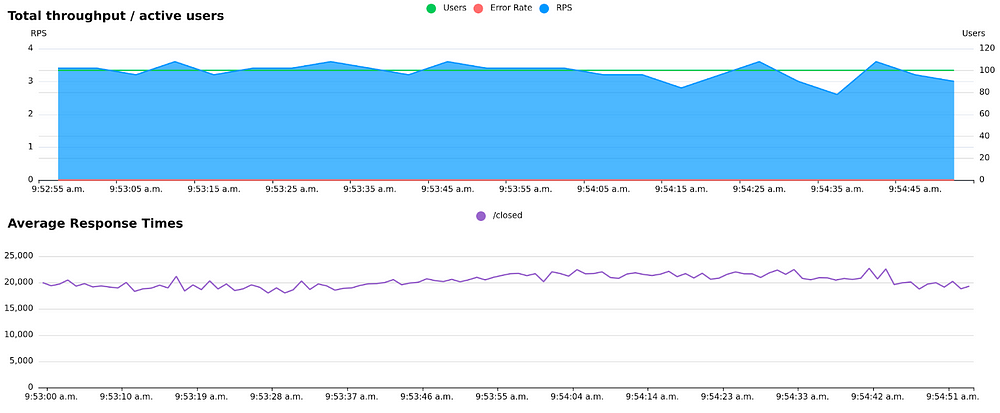
Unfortunately, a closed workload comes with some limitations. Lets assume, for example, that we have a system that struggles with some sort of periodic issue (maybe a batch job, maybe a database doing indexing or something similar). If you run a closed workload you‘ll get variations in throughput:
Closed load: Variations in response times cause variations in throughput
In some circumstances you can generate quite misleading results due to coordinated omission: in short, a load test where the throughput goal is not met all the time will have artificially low average response times, because there were more requests happening when response times were low.
Open workload: Ensure constant load and reproducible results

Open workload is the honey badger of load tests — it doesn’t care about response times and keeps going at the pace you told it to. In an open load test you might target 80 transactions per second, with an uncapped or very large number of concurrent users. It is sometimes referred to as arrival rate.
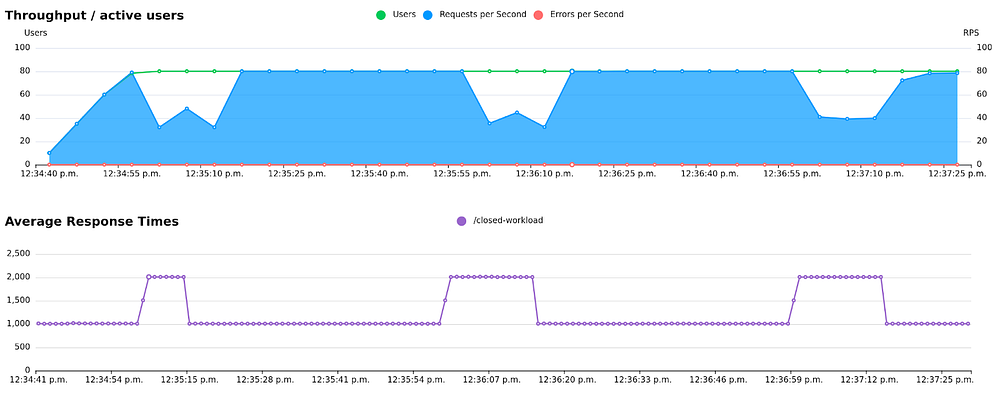
In the previous example of a system with varying response times, you’d get something more like this:
Open load: Stable throughput despite variations in response times
The primary result/outcome variable of a load test using an open workload is response times, typically measured in milliseconds or seconds.
Most load testing tools support a type of adaptive sleep that allows you to simulate open load (constant_pacing in Locust, Constant Throughput timer in JMeter). Some tools also support open load outright, by launching additional users/threads if throughput drops below a target level. It works by filling out the time between iterations/requests so that requests are sent at a stable pace, regardless of response times:
class OpenWorkload(HttpUser):
wait_time = constant_pacing(10) # max 1 iteration per 10 seconds
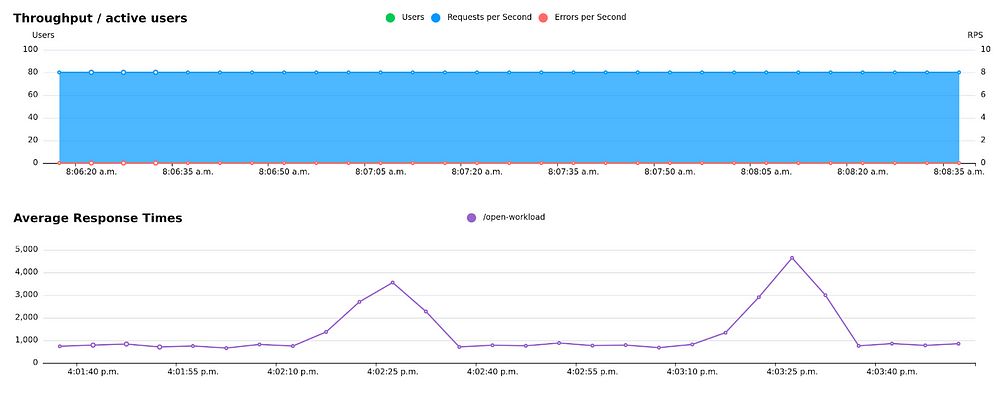
...In this case, lets assume we don’t know anything about our system’s capacity, so we start out by launching 600 users:
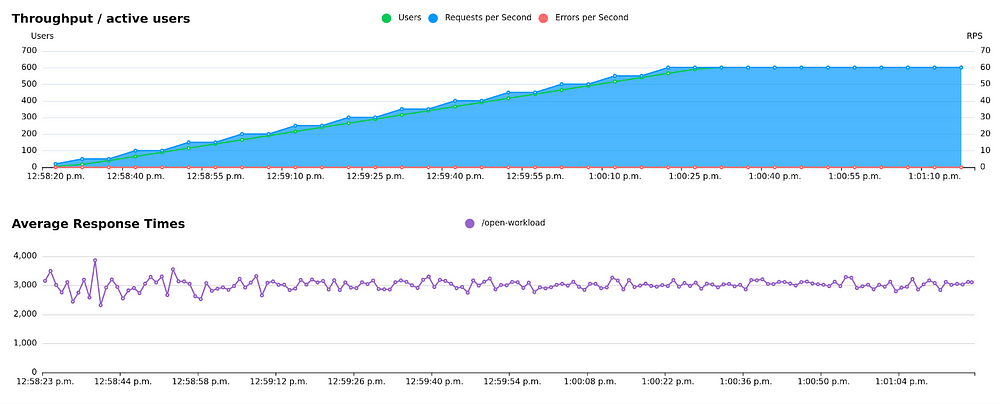
Looks nice, right? Assuming your test scenario is realistic and validates its the responses correctly (more about that in a later post), and you run this test for a while, you can be reasonably confident that you can handle 60 requests per second. But your limit might be 61, or it might be 200. You won’t know until your system gets overwhelmed. And equally important, you won’t know how it fails when it reaches its limit. Hopefully it will just gracefully become a little slower, but it could also just crash, or start giving everyone error responses.
Similarly, if your test does fail, you also don’t really know what the limit is. Let’s say your system can only handle ~70 transactions per second, but you target 100. Your load generator is going to spam 100 requests per second, quickly overwhelming your system and resulting in errors. This might fill create a bunch of error logs, crash services and otherwise create problems. And because the system overflows so quickly you don’t really know if your system could maintain ~70 transactions/s for more than a few seconds.
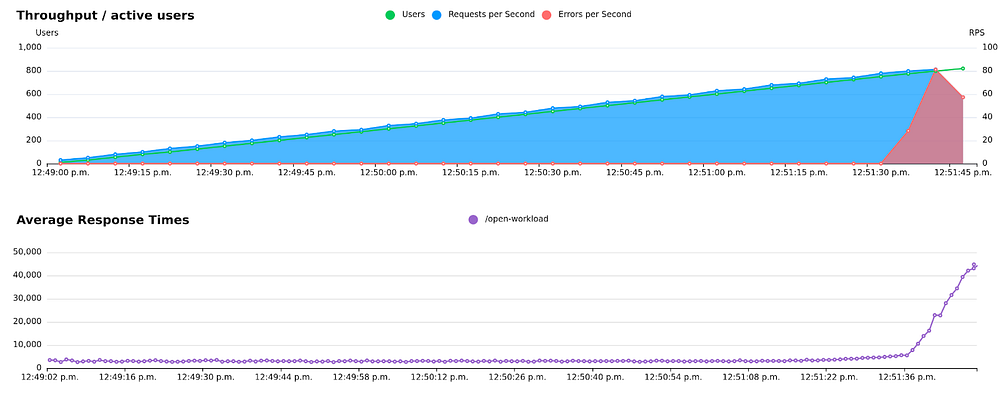
800+ users doing 1 request per 10 seconds. Around 70 RPS you can see the response times start to increase, but because there is no limit on the throughput we quickly overload the system, and we start to get error responses.
So when is open load testing useful?
If you want to do repeated runs to understand resource utilization, then you should use open load so you can compare identical runs with different versions of the system under test. A closed load will be impacted by your system’s response times, whereas with an open load the load is (theoretically) stable regardless of response times.
Sometimes you need to give some thought to how your users might behave — are they a limited group of people who might “naturally” have a closed behaviour, because they wont request the next page/API call until the previous one finished? Or are your client applications making requests at the same rate regardless of response times? Or maybe your users are impatient and will start refreshing the page once response times exceed a certain threshold, increasing the load as response times deteriorate?
Closing thoughts
If all of this feels overwhelming, I want to help! Reach out to me either on LinkedIn or on the Locust Discussions forum.
Lars Holmberg • 2024-08-28
Back to all posts